Go1.7からSSAが導入された
初めに
Go 1.7がリリースされる。目玉の一つは、SSA-IRが導入されたことだろう。Go1.7でSSAが入るんだけど、SSAって何?と居酒屋で聞かれたことが本稿の発端だった。私の知識だけでは包括的な説明にならなかったので、いろいろ調べつつそれをまとめた。 以下、一般的な話ではなく、なるべくGoに絞って話を進めている(コンパイラのコードははcmd/compile/internal/gcあたりにある)。より一般的な話は、参考文献等を示したのでそちらを参考にしてほしい。いろいろ調べて、Goに追加されたSSAについて知るべきことは、SSAが何か?よりも、SSA導入したGoがどうなったか、であると思った。
SSAとは何か
SSA とは Static Single Assignmentの略だ。一つの変数への代入は一度しか行われてない事が確約できる形式のコードだ。この形式のコードは、最適化が行いやすいらしく、例えばSSAが前提と成ってる最適化手法(GVNなど)もある。SSAが導入された経緯の説明の前に、まずは現状(1.6まで)についてまとめる。
なぜ最適化が必要か
SSAは最適化のために利用される。このためコンパイラが行っている最適化について知る必要がある。まず、最適化なしのコンパイラが何をしているかを説明する。(もう知ってるよという方は、「問題」から入っていただければ良い。)簡単に言えば、プログラムを一文一文、愚直な機械語に変換している。
a := 3 // (a)
b := 4 // (b)
c := a + b // (c)
というコード片があるとしよう。これを最適化せずにコンパイルすると、以下のように換える。
MOVQ $0x3 0x10(SP) // (1) <-- (a)
MOVQ $0x4 0x8(SP) // (2) <-- (b)
MOVQ 0x10(SP) BX // (3) <-- (c)
MOVQ 0x8(SP) R8 // (4) <-- (c)
ADDQ R8 BX // (5) <-- (c)
MOVQ BX 0(SP) // (6) <-- (c)
コメントに対応関係を示したが、(a)~(c)はそれぞれ(1)~(6)へと変換される。まず、(a),(b)のように定数を変数に代入する場合、これを変数のアドレス(スタックに取られた変数用の領域)に転送する。次に(c)では加算を行うが(3),(4)では先ほ変数に格納した値をBXとR8レジスタに読み込む。そして、これらは(5)で加算され、(6)で計算結果が再び変数領域に書き込まれる。 では、この機械語列をもっと効率的に実行するにはどうしたら良いだろうか。上の機械語列、(1)~(4)は、計算すべき値を一度変数に格納して、レジスタに読み直すということをしてるが、これは無駄である。初めから計算すべき値だけをレジスタに乗せれば良い。 最適化がなされていないコードはこのように元のコードと生成された機械語の対応関係が明らかな場合が多い。これは、ソースコードを一文一文、素直にコンパイルしているだろうことがうかがえる。
Go1.6での最適化
素直に変換したコードには無駄があった。最適化は、この非効率なコードをより効率的なものへと、機械的に置き換える。Goのコンパイラは1.6以前、最適化と言ったら主に2つあった(-Nフラグで切り替えることのできる最適化を主なものとしてる)。それらはniloptとregoptという関数でそれぞれ行われている。上のコードは、regopt によって効率的に置き換えられるため、regoptについて話す。(コードはreg.go)
一般にはレジスタ割り付けと呼ばれるものだろう。CPUでの演算、すなわちコンピューターで行うほとんどの演算は、レジスタに計算すべき値を読み込んで行う。しかしレジスタは数が限られているので、これらをいかに効率よく使うかという問題が発生する。生成された命令で、使ってるレジスタをマークしていき、もし空いているレジスタがあればそちらを使うようにする。すると、以下のような状態になる。
MOVQ $0x3, CX
MOVQ $0x4, AX
MOVQ CX, BX
MOVQ AX, R8
ADDQ R8, BX
MOVQ BX, AX
(1)や(2)で行われていた、変数への書き出しがなくなって、レジスタ(そういえば、AXやBXなどがレジスタであることを言い忘れた。一般的なレジスタ一覧はこちら)への直接書き込みに変換されていることがわかる。
しかしまだ、効率が良くない。ADDが利用してるレジスタであるR8やBXに直接読み込みしてほしい。
この後、peephole最適化というものが行われる。局所最適化とも呼ばれるが、要は、コードを眺めて、あぁここは明らかに効率悪い、こうしましょうね。というものをピックアップし、アドホックに行う最適化のことである。ここでは、レジスタの無駄なコピーを省くというpeephole最適化が適用されており、以下のようなコードになる。
MOVQ $0x3, BX
MOVQ $0x4, AX
ADDQ AX, BX
ここまでくれば、効率良い機械語へ変換できている。具体的にどの程度差がつくか、測ってみてもいいかもしれない。
Go1.6までの問題?
問題というより、Go1.6の最適化はまだ未発達な部分がある。手をつけてないと言った方が正しいだろう。「Go 1.5からGo言語が全てGoでかかれるようになったのは周知の事実だ。これを踏まえて、GoのIRもSyntax-tree-basedのものから近代的なSSA-basedのものに変えれば、今のコンパイラでは実装が難しい(Go1.4時点)、様々な最適化が行えるようになる(意訳)」というくだりからSSAの提案書は始まっている。つまり、明示的にこの最適化がしたい!というより、とりあえずSSAにしておけば種々の最適化が導入できそうだよね、というモチベーションっぽい。
SSA導入で何が変わったか
最適化が実装しやすくなる、という名目で導入されたSSA。では1.7ではどのような最適化が入っているのか。実際にリストアップしてみたのだが、かなりの数入ってることがわかる。それぞれ対応する関数が書かれてるので、中身はそちらでみれるようだ。
var passes = [...]pass{
// TODO: combine phielim and copyelim into a single pass?
{name: "early phielim", fn: phielim},
{name: "early copyelim", fn: copyelim},
{name: "early deadcode", fn: deadcode}, // remove generated dead code to avoid doing pointless work during opt
{name: "short circuit", fn: shortcircuit},
{name: "decompose user", fn: decomposeUser, required: true},
{name: "opt", fn: opt, required: true}, // TODO: split required rules and optimizing rules
{name: "zero arg cse", fn: zcse, required: true}, // required to merge OpSB values
{name: "opt deadcode", fn: deadcode, required: true}, // remove any blocks orphaned during opt
{name: "generic domtree", fn: domTree},
{name: "generic cse", fn: cse},
{name: "phiopt", fn: phiopt},
{name: "nilcheckelim", fn: nilcheckelim},
{name: "prove", fn: prove},
{name: "loopbce", fn: loopbce},
{name: "decompose builtin", fn: decomposeBuiltIn, required: true},
{name: "dec", fn: dec, required: true},
{name: "late opt", fn: opt, required: true}, // TODO: split required rules and optimizing rules
{name: "generic deadcode", fn: deadcode},
{name: "check bce", fn: checkbce},
{name: "fuse", fn: fuse},
{name: "dse", fn: dse},
{name: "tighten", fn: tighten}, // move values closer to their uses
{name: "lower", fn: lower, required: true},
{name: "lowered cse", fn: cse},
{name: "lowered deadcode", fn: deadcode, required: true},
{name: "checkLower", fn: checkLower, required: true},
{name: "late phielim", fn: phielim},
{name: "late copyelim", fn: copyelim},
{name: "phi tighten", fn: phiTighten},
{name: "late deadcode", fn: deadcode},
{name: "critical", fn: critical, required: true}, // remove critical edges
{name: "likelyadjust", fn: likelyadjust},
{name: "layout", fn: layout, required: true}, // schedule blocks
{name: "schedule", fn: schedule, required: true}, // schedule values
{name: "flagalloc", fn: flagalloc, required: true}, // allocate flags register
{name: "regalloc", fn: regalloc, required: true}, // allocate int & float registers + stack slots
{name: "trim", fn: trim}, // remove empty blocks
}
SSA形式に変換されたコードは、ウォーターフォール的にこれらの最適化ステージを全て通る。そして出来上がったコードから、機械語が生成される。
さて、実装者はデバッグ用に、便利な機能を残してくれている。
GOSSAFUNC=main go build
でプログラムをコンパイルしてみてほしい。GOSSAFUNCにはデバッグしたい関数名を入れる。コンパイル結果と別に、ssa.htmlというHTMLが生成されているだろう。これは、各最適化ステージ別にその時のSSAコードの様子を示してくれる。以下は、最初のコードをコンパイルしてみた結果だ。early deadcodeというステージで、関数ごと消されている。これはテスト用に作った関数で、最終的には_=cとしていたためである。

最適化の結果、ベンチマークのほぼ全てが5~35%の高速化を達成しており、バイナリのサイズも20%ほど小さくなっている。これは無駄なコードが最適化により削れたことの恩恵だ。しかし一方で、コンパイル時間(純粋なコード生成の時間)は10%ほど増えている。他の人との話をすり合わせてわかったが、go buildの時間は改善してるので、リンカなどが早くなったためにビルド全体の時間は改善されたようだ(?)。
終わりに
先日、Go Release party TokyoでSSAについて喋ってきた。SSAとは何か?という話をするつもりだったが、GoのSSAについてはほとんど触れてなかったため、本稿を書いた。また、遅くなったが、稿末に質疑応答でペンディングしてた質問への回答も書いているので参考にしていただきたい。
質疑への回答
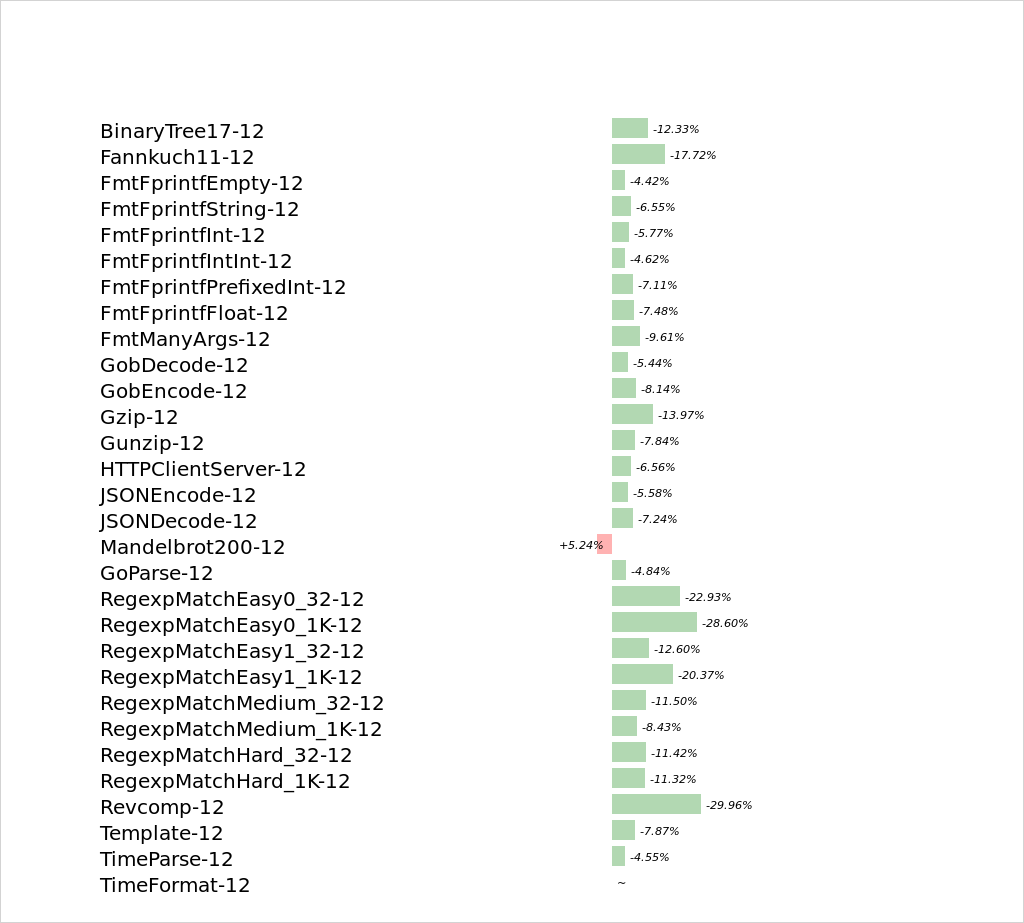
Q1. Go-1.7で速度が落ちてるベンチマークもあるがその理由は?
A1. まず結果の図はこちら。Manderbrotが遅くなってる。MLに回答があるが、Mandelbrotはコードにループのネストがある。peephole最適化が行っていたレジスタ割り当てについてはSSAの方が劣っているようだ。ここは今後の改善が見込まれるところだといっている。
{kind=link}
Q2. こう書けば早くなる、というコードはあるか?
A2.一般的にループ最適化に弱いようで、上のMandelbrotも示すように複雑なループはGo1.6以前の方が積極的に最適化されてたようだ。もしループのネストが多くあるようなコードの場合は、手動で最適化した方が速度は出ると思われる。
参考
- レジスタ割り付け
- コンパイラの構成と最適化, 中田育夫, 朝倉書店
- Go 1.7 toolchain improvements, Dave chenny
« Javaのテスト実行時間を62%削るvmvmを試してみた
メンテ方法を忘れたgithub pageをAIで復活させた »